Early in my career as a business intelligence consultant I was on assignment to a federal agency that produced a report to Congress that showed the impact the agency had in each congressional district. My task on this project was to identify how much money the agency expended with its suppliers in each district. We acquired a set of data from the agency’s purchasing and contracts database, enhanced the data with the addition of congressional district identifiers based on supplier addresses, and produced the requested report. Our celebration on a job well done was cut short when a skeptical congressman from a rural district asked for details on the agency’s $300 million contract with a supplier in his district. It turns out the contract in question was for $30 million and not the $300 million reported. The contract record in the source data set included an extra zero. The agency suffered embarrassment and loss of credibility because the congressmen knew his district well enough to question whether he had a $300 million business in his midst but we didn’t know the agency’s data well enough to flag a $300 million contract as suspicious.
Had we known about and applied data profiling to the contracting data before producing the Congressional impact report we could have avoided the embarrassing incident with the congressman. Just like the coaching staff of a football team scouts an unfamiliar opponent to prepare for a game we could have scouted the unfamiliar data set to prepare a game plan for reporting. Football scouts learn the height and weight of the opponent’s players. They identify the fastest and slowest players. They find out how long each player has been in the league and how long they have been with their current team. They identify the special talents of the team’s star players and review the formations and plays the team uses in different game situations. Armed with this information the coaching staff prepares a strategy and game plan to increase the chances of a successful outcome.
In much the same way as football scouts, practitioners of business intelligence create profiles (see figure below) to learn the characteristics of new and unfamiliar sources of data. They count the number of tables in the database and number of rows in each table. They gather statistics about each column. They find out if numeric columns contain both positive and negative values, whether address tables contain only domestic or also include international addresses, whether phone number columns included international format phone numbers or have extensions embedded after the phone number. They look for missing or incomplete data values, potential data quality problems, and a range of other data conditions to expand their understanding of the data source.
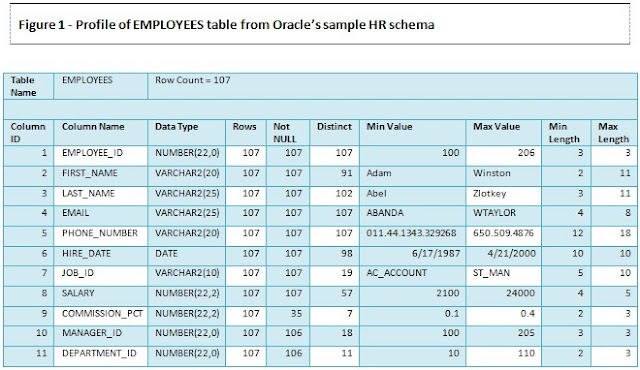
The report above is just the starting point to provide a comprehensive overview of a data set. There are a number of other profiling reports that drill deeper into different details of the data set all with the goal of learning what is and isn’t possible with a data source and how to efficiently and accurately report on the data . The primary purpose is to confirm that the data you plan to work with is in fact what you think it is and that it will support the reporting requirements you intend to use it for. You can’t just look at a data model for a source and assume it has what you need because you see the right table names and column names. You may discover that columns are empty or contain very different data from what you expected based on the column name. Application developers frequently change the usage of columns without modifying table structures or updating documentation and end users are famous for figuring out workarounds that involve putting data into fields that were intended for other purposes. The data profile will reveal the actual usage of data.
From the profile you can also measure transaction volumes over time and identify growth trends – information you need to support capacity planning and disk storage requirements for a data warehouse. The profile reveals peaks and valleys in transaction volume that help to plan maintenance cycles for the data warehouse. And the profile exposes the nature and scope of data quality problems that could derail your project if not properly planned for.
Whether you are doing a one-time reporting project with a one-off data set or setting up a data mart or data warehouse for long-term use, data profiling of the source data is a critical first step that should be completed before anybody delivers reports. Employing data profiling during the early analysis phase of business intelligence and data warehousing projects produces three significant benefits for the sponsoring organization.
- Accurate Reporting
Without data profiling, data warehouse data model design choices are educated guesses at best and users are left to make risky assumptions when creating reports. With the benefit of data profiling the structure and labeling of the data warehouse data model and user presentation semantic layer represent the true state and usage of the source data. Data quality problems have been identified, documented, and mitigated. And users who run reports and ad hoc queries have a road map to understand what is and is not reasonable for report results.
- On-time Project Delivery
All too often the first good look at source data takes place when developers start testing data warehouse load processes. At this stage in a project the discovery that assumptions about data were incorrect or that there are serious data quality issues means that instead of moving forward on schedule developers must reopen closed phases of the project plan to redo data model and load process designs and extend the load process development phase to complete unplanned data quality work. Thorough data profiling during the analysis phase of the project eliminates data surprises that delay the development phase.
- High Performance and Availability
No one wants to see databases crash when disk space runs low or wait sessions back up in the queue. And even if the database is up users won’t come back for more and won’t work the data as hard as they can if poor query response times leave them hanging. Using profiling to learn characteristics such as how data values are distributed across rows of data, the relationships between data elements, and the size and growth characteristics of data provides a solid basis to make decisions about storage options, index usage, and data partitioning that maximize query throughput and keep the data warehouse database running smoothly.
There are many data profiling tools available from vendors such as Computer Associates, SAP, Trillium and Oracle to name a few. There are also open source profiling solutions and for simple projects you can do your own profiling solution using any SQL query tool. The bottom line is if you are using data sets for business intelligence activities you should be profiling your data.


